GenAI Isn't the Problem. Your Architecture Is.
Models propose, systems decide
By now you've seen the MIT report from 2025 that claims only ~5% of enterprise AI pilots deliver measurable business impact. The other 95% quietly stall out or die on the vine. The report points to many recurring reasons for those failures, here are a select few:
- AI tool integrations fail to fit cleanly into enterprise workflows in a way that delivers real value
- GenAI solutions don't retain context or adapt to operational feedback in a way that meaningfully feeds back into the system
- Most deployments boost individual productivity but fail to meaningfully change how systems actually work
I've seen these truths in my daily work, both as a user and as an engineer. But I don't think these problems stem from GenAI itself. I think these problems stem from probabalistic models being dropped into deterministic workflows. The report states the following in it's final section:
The most forward-thinking organizations are already experimenting with agentic systems that can learn, remember, and act autonomously within defined parameters.
I think within defined parameters is doing a herculean amount of lifting in that sentence. To explain what I mean, I need to tell you about the Infinite Improbability Drive.
In The Hitchhiker's Guide to the Galaxy, the Infinite Improbability Drive is the core of the Heart of Gold, the crew's interstellar spaceship. When activated the Infinite Improbability Drive routinely causes wildly improbable and chaotic events, like turning missiles into a whale and a bowl of petunias. It's a notoriously unreliable and dangerous technology that can change the physical state of the ship and its crew. And yet, it's also the component of the ship that makes instantaneous, universe-bending jumps possible. The rest of the ship surrounds the Infinite Improbability Drive and provides structure, controls, and safety for its crew (most of the time).
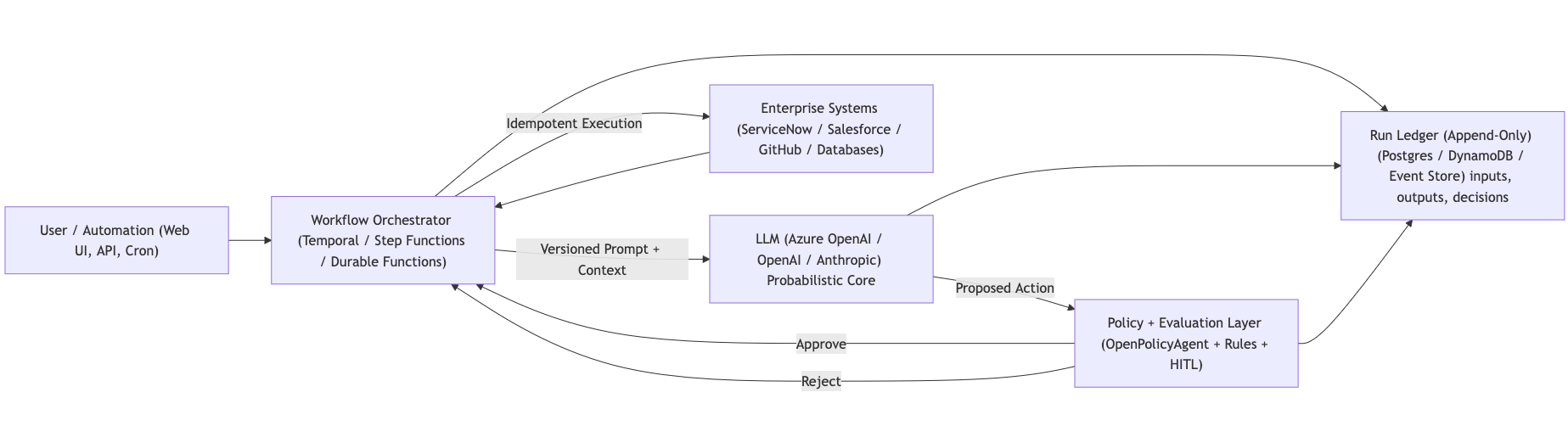
In your AI-enabled applications, an LLM plays the same role as the drive. It generates powerful, probabilistic answers at incredible speed. Just like the Heart of Gold, the surrounding application needs to provide structure, controls, and safety for its users and admins. The LLM can produce incredible results, but the LLM cannot own state, enforce rules, or safely recover from failure on its own. That responsibility belongs to the rest of the application. When an LLM is narrowly focused inside of a system with clear execution rules and control points, you end up with something that might just actually provide value in production.
In 2026, most enterprise GenAI application failures are not model-quality problems. They're control-plane problems. Organizations are dropping probabilistic systems into workflows that were built to be predictable and auditable without adding the architectural pieces to protect the rest of the system from the new chaos.
If you want LLMs to play a core role in your systems, you must clearly separate responsibilities. The model should be "just another API" inside a workflow, and the workflow itself owns execution, retries, and state transitions. Inputs, tool calls, outputs, and side effects need to be versioned, replayable, and diffable.
An LLM's output should never mutate enterprise systems of record through indirect action (i.e. LLM output being forwarded to a system of record without policies) and certainly should not be allowed to modify systems of record directly. It should only propose actions. A governing orchestration layer decides what is allowed, enforces policy and idempotency, and applies evaluation gates before anything mutates real systems.
This is where policy engines like Open Policy Agent (OPA) are helpful. A well architected system with OPA can answer the following questions using "old school" (no AI) techniques:
- Is this action allowed?
- Does it require approval?
- What constraints apply?
Your policies should dictate the answers to those questions, not some clanker.
Every input, tool call, policy decision, and output should be written to an append-only run ledger so executions are replayable and auditable. Models may suggest actions, and an event-sourced/auditable execution system records not only what happened, but also records why the actions happened. Side effects occur only through controlled executors with idempotency keys so retries don't duplicate work. Higher-risk actions can be routed through a human approval queue as a deliberate control.
All of this might sound like overkill, and in some AI-enabled applications some parts of this proposed system might not be necessary. But the system around the LLM should be predictable where it matters for your use case (e.g. state changes, side effects, governance decisions). Once an LLM's output is captured as a versioned input the orchestration, policy, and execution layers will behave the same way every time. The non-deterministic part of the system needs to end at the model boundary. Once the LLM produces an output, that output should be treated as data. Not as ongoing behavior.
And yes, it's tempting to say “we'll just route all important decisions to a human.” That feels safe, but that approach introduces its own failure modes. More on that in a future post.
GenAI feels wrong in many enterprises because it's being sprayed across workflows without changing the underlying architecture. We're inserting probabilistic components into environments that were designed for predictability, auditability, and control. Then we're pretending like nothing else needs to change.
This isn't an AI maturity issue. It's a systems design failure. GenAI-enabled apps aren't adapting well because we're treating AI like the application itself, when it should be treated more like infrastructure.
The enterprise organizations getting this right aren't "using more AI." They're redesigning the systems around it. They're narrowing the use of AI to precise, value-adding features. These organizations understand that models should suggest data/actions, but the surrounding system must decide, execute, and record.
To bring us back to the original point: one of the reasons enterprise GenAI integrations fail is because we're treating these statistical engines like finished applications instead of powerful components that need to be contained. When you design your system so that the boundary of the model is well-contained as described in this article, GenAI might actually start providing value in production. You know, that thing everyone hoped it would do in the first place.
Said differently: get this right and you're the Heart of Gold. Get it wrong and you're the bowl of petunias, with just enough time for one last thought: "oh no, not again."
If you find yourself also thinking about these problems, let's nerd out. Drop me a line anytime at kyle@directiv.ai.